Narrow-band Deep Speech Separation
Multi-channel Narrow-band Deep Speech Separation with Full-band Permutation Invariant Training
Abstract
[1] Changsheng Quan, Xiaofei Li. Multi-channel Narrow-band Deep Speech Separation with Full-band Permutation Invariant Training. In ICASSP 2022. [Code], [Pdf], [Results], [Examples]
This paper addresses the problem of multi-channel multi-speech separation based on deep learning techniques. In the short time Fourier transform domain, we propose an end-to-end narrow-band network that directly takes as input the multi-channel mixture signals of one frequency, and outputs the separated signals of this frequency. In narrow-band, the spatial information (or inter-channel difference) can well discriminate between speakers at different positions. This information is intensively used in many narrow-band speech separation methods, such as beamforming and clustering of spatial vectors. The proposed network is trained to learn a rule to automatically exploit this information and perform speech separation. Such a rule should be valid for any frequency, thence the network is shared by all frequencies. In addition, a full-band permutation invariant training criterion is proposed to solve the frequency permutation problem encountered by most narrow-band methods. Experiments show that, by focusing on deeply learning the narrow-band information, the proposed method outperforms the oracle beamforming method and the state-of-the-art deep learning based method.
Abstract
[2] Changsheng Quan, Xiaofei Li. Multichannel Speech Separation with Narrow-band Conformer. arXiv preprint arXiv:2204.04464. [Code], [Pdf], [Results], [Examples]
This work proposes a multichannel speech separation method with narrow-band Conformer (named NBC). The network is trained to learn to automatically exploit narrow-band speech separation information, such as spatial vector clustering of multiple speakers. Specifically, in the short-time Fourier transform (STFT) domain, the network processes each frequency independently, and is shared by all frequencies. For one frequency, the network inputs the STFT coefficients of multichannel mixture signals, and predicts the STFT coefficients of separated speech signals. Clustering of spatial vectors shares a similar principle with the self-attention mechanism in the sense of computing the similarity of vectors and then aggregating similar vectors. Therefore, Conformer would be especially suitable for the present problem. Experiments show that the proposed narrow-band Conformer achieves better speech separation performance than other state-of-the-art methods by a large margin.
Method
This method includes two main parts: the first part is to separate in each frequency; the second part is about how to solve the frequency permutation problem to train the network.
The following content assumes we have M microphones and N speakers.
1) Narrow-band Deep Speech Separation
Prepare Narrow-band Input. Why Narrow-band? It carries spatial information of speakers

Network Processing: Train network to separate different speakers in narrow-band

2) Full-band Permutation Invariant Training
Frequency Permutation Problem—How to find the correspondence of separated signals accross frequencies? One possible frequency permutation for two-speaker case:
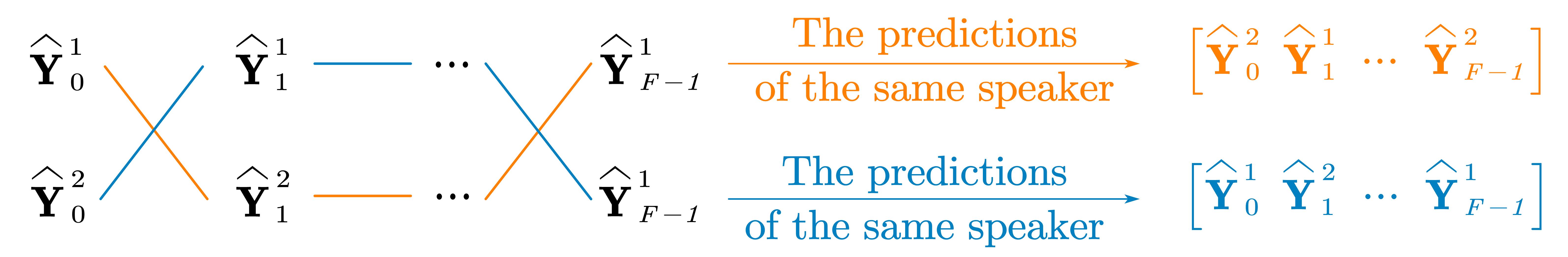
Our solution for FPP: Frequency Binding—Force the separated signals at the same output position to belong to the same speaker
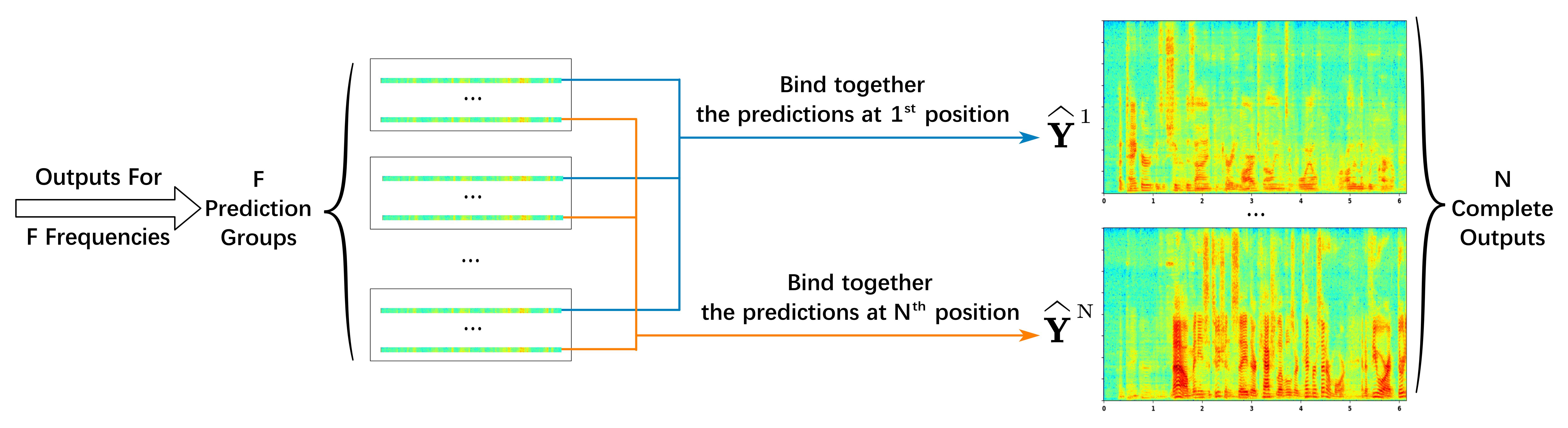
Loss Calculation
$$ fPIT(\boldsymbol{\rm \widehat{Y}}^{1},\ldots, \boldsymbol{\rm \widehat{Y}}^{N}, \boldsymbol{\rm {Y}}^{1},\ldots,\boldsymbol{\rm {Y}}^{N})=\mathop{min}_{p\in \mathcal{P}}\frac{1}{N}\sum_n \mathcal{L}(\boldsymbol{{\rm {Y}}}^n,\boldsymbol{{\rm \widehat{Y}}}^{p(n)}) $$
where P is the set of all possible frequency permutations, and p is one possible frequency permutation in P. And the negative SI-SDR [3] is used as the loss function for each prediction-target pair.
Network
NB-BLSTM
The network used in our paper [1] is composed of two layers of bidirectional LSTM and one fully connected layer.
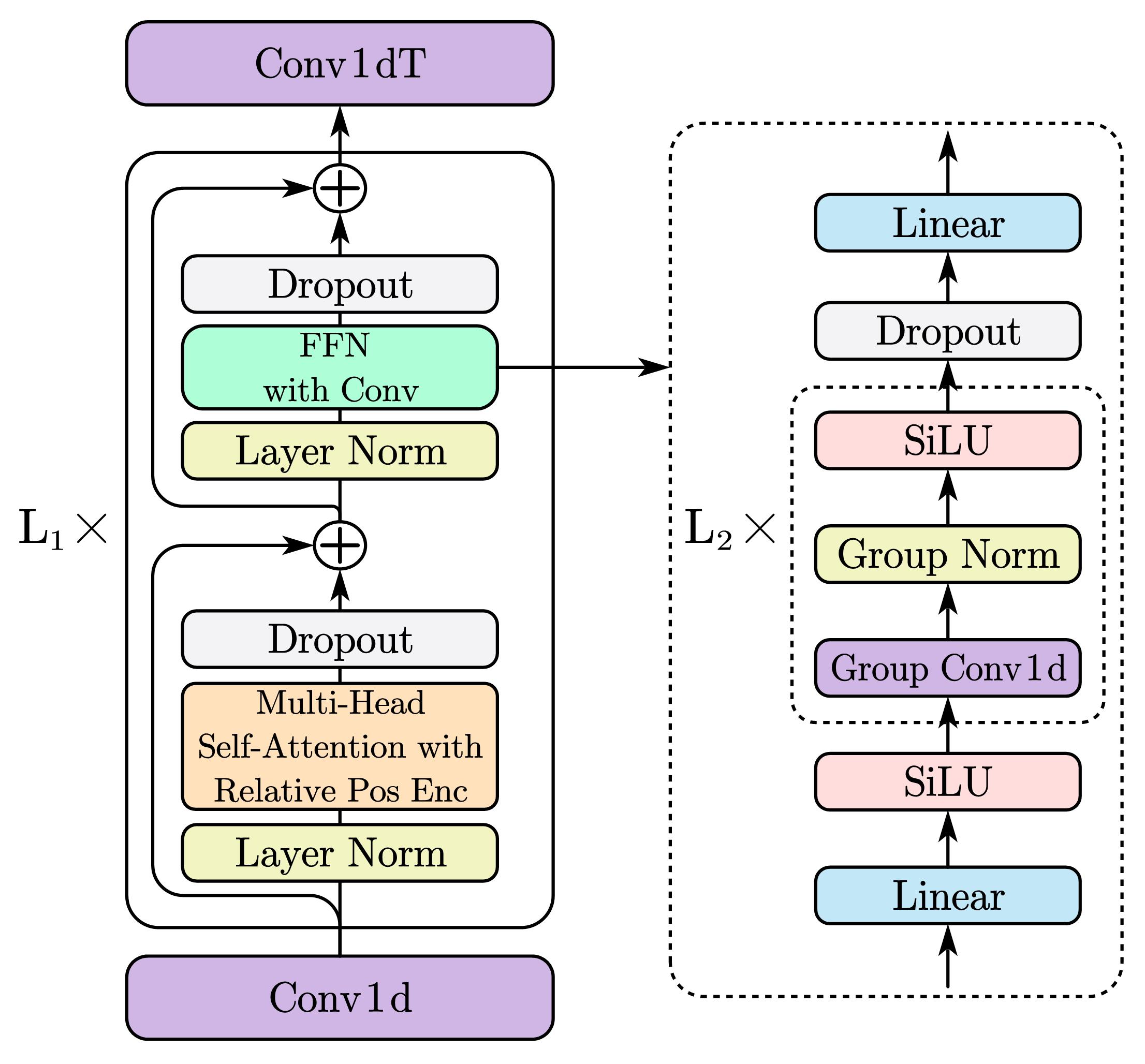
NBC: Narrow-band Conformer
The narrow-band conformer (NBC) proposed in our recent work [2] is used to replace the BiLSTM network used in [1], as the narrow-band speech separation shares a similar principle with the self-attention mechanism and convolutions in Conformer, thus is more suitable for narrow-band speech separation than BiLSTM. The narrow-band conformer significantly improves the performance of the BiLSTM network [1].
The narrow-band conformer structure:
Results
Performance Comparision with SOTA Speech Separation Methods for 8-Channel 2-Speaker Mixtures
| Model | #param | NB-PESQ | WB-PESQ | SI-SDR | RTF |
|---|---|---|---|---|---|
| Mixture | - | 2.05 | 1.59 | 0.0 | - |
| Oracle MVDR [4] | - | 3.16 | 2.65 | 11.0 | - |
| FaSNet-TAC [5] | 2.8 M | 2.96 | 2.53 | 12.6 | 0.67 |
| SepFormer [6] | 25.7 M | 3.17 | 2.72 | 13.2 | 1.69 |
| SepFormerMC | 25.7 M | 3.42 | 3.01 | 14.9 | 1.70 |
| NB-BLSTM [1] (prop.) | 1.2 M | 3.28 | 2.81 | 12.8 | 0.37 |
| NBC [2] (prop.) | 2.0 M | 4.00 | 3.78 | 20.3 | 1.32 |
Examples
Please open this page with Edge or Chrome, and not use Firefox. The audio playing is problematic in Firefox.
| Id | Mix | Oracle MVDR [4] | FaSNet-TAC [5] | SepFormer [6] | SepFormerMC | NB-BLSTM [1] (prop.) | NBC [2] (prop.) |
|---|---|---|---|---|---|---|---|
| 1 | |||||||
| 2 | |||||||
| 3 | |||||||
| 4 | |||||||
| 5 | |||||||
| 6 |
Source Code
These works are open sourced at github, see [Code], [NBSS with fPIT Pdf], [Narrow-band Conformer Pdf]. If you like this work and are willing to cite us, please use:
@inproceedings{quan_multi-channel_2022,
title = {Multi-channel {Narrow}-band {Deep} {Speech} {Separation} with {Full}-band {Permutation} {Invariant} {Training}},
booktitle = {{ICASSP}},
author = {Quan, Changsheng and Li, Xiaofei},
year = {2022},
}
and
@article{quan_multichannel_2022,
title = {Multichannel {Speech} {Separation} with {Narrow}-band {Conformer}},
journal = {arXiv preprint arXiv:2204.04464},
author = {Quan, Changsheng and Li, Xiaofei},
year = {2022},
}
References
[1] Changsheng Quan, Xiaofei Li. Multi-channel Narrow-band Deep Speech Separation with Full-band Permutation Invariant Training. In ICASSP 2022.[2] Changsheng Quan, Xiaofei Li. Multichannel Speech Separation with Narrow-band Conformer. arXiv preprint arXiv:2204.04464
[3] Jonathan Le Roux, Scott Wisdom, Hakan Erdogan, and John R. Hershey. SDR – Half-baked or Well Done? In ICASSP 2019.
[4] https://github.com/Enny1991/beamformers
[5] Yi Luo, Zhuo Chen, Nima Mesgarani, and Takuya Yoshioka. End-to-end Microphone Permutation and Number Invariant Multi-channel Speech Separation. In ICASSP 2020.
[6] C. Subakan, M. Ravanelli, S. Cornell, M. Bronzi, and J. Zhong. Attention Is All You Need In Speech Separation. In ICASSP 2021.